Detail ran a Bradley-Terry tournament using Sonnet 4.6 as judge to show its bug findings rank at the 88th percentile vs. code review bot findings.
Key Takeaways
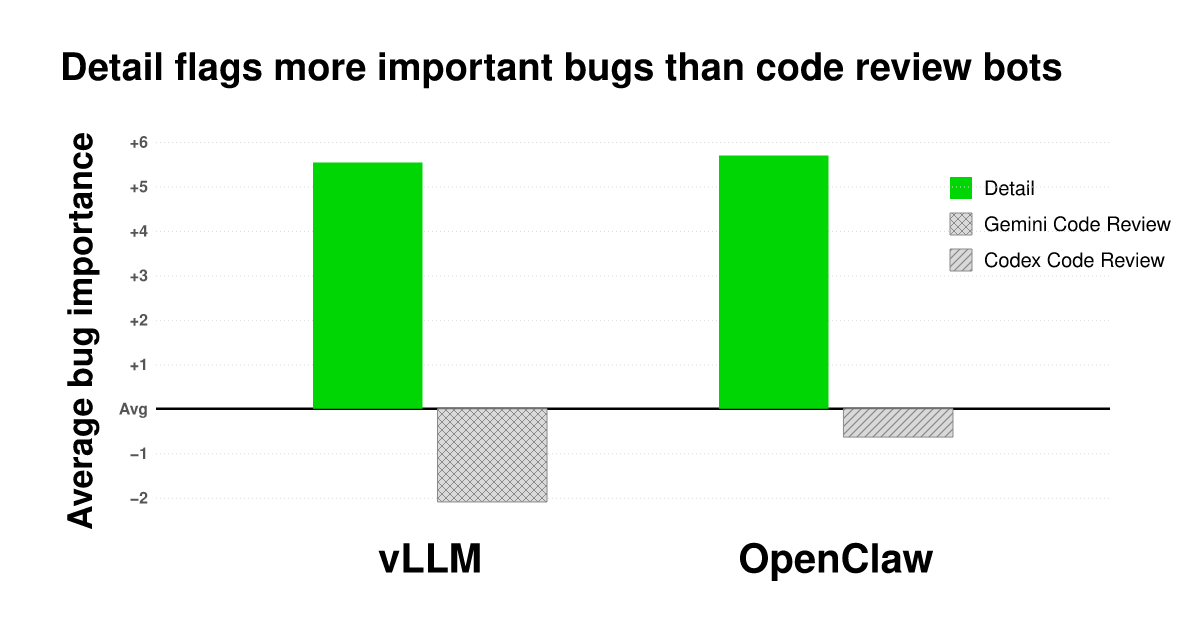
Detail compared one week of PR bot comments on OpenClaw and vLLM against its own findings using pairwise LLM judging fed into a Bradley-Terry ELO model.
After normalizing finding depth via one-sentence summarization, Detail bugs averaged +5 standard errors above the combined dataset mean, beating a random CR bot finding ~91% of the time.
Separately, 82.9% of Detail findings were marked correct by humans or agents over the last two months, validating importance scores are not just hallucinated severity.
Example finding in PostHog: a refactor replaced a privacy-aware ctx.get_sandbox_environment() call with a direct DB query, dropping the private + created_by check and exposing team members’ secret env vars despite Greptile, Codex, Hex Security, and Copilot all running on the PR.
Claude Code baseline attempts either surfaced already-reported bugs or misread fixed code (reporting a hot-loop bug while missing the one-line guard directly below it).
Hacker News Comment Review
No substantive HN discussion yet; one commenter questioned whether the post was a paid placement, with no rebuttal or technical follow-up.