
The inside story of how ChatGPT was built – OpenAI cofounder John Schulman
Watch on YouTube ↗ Summary based on the YouTube transcript and episode description.
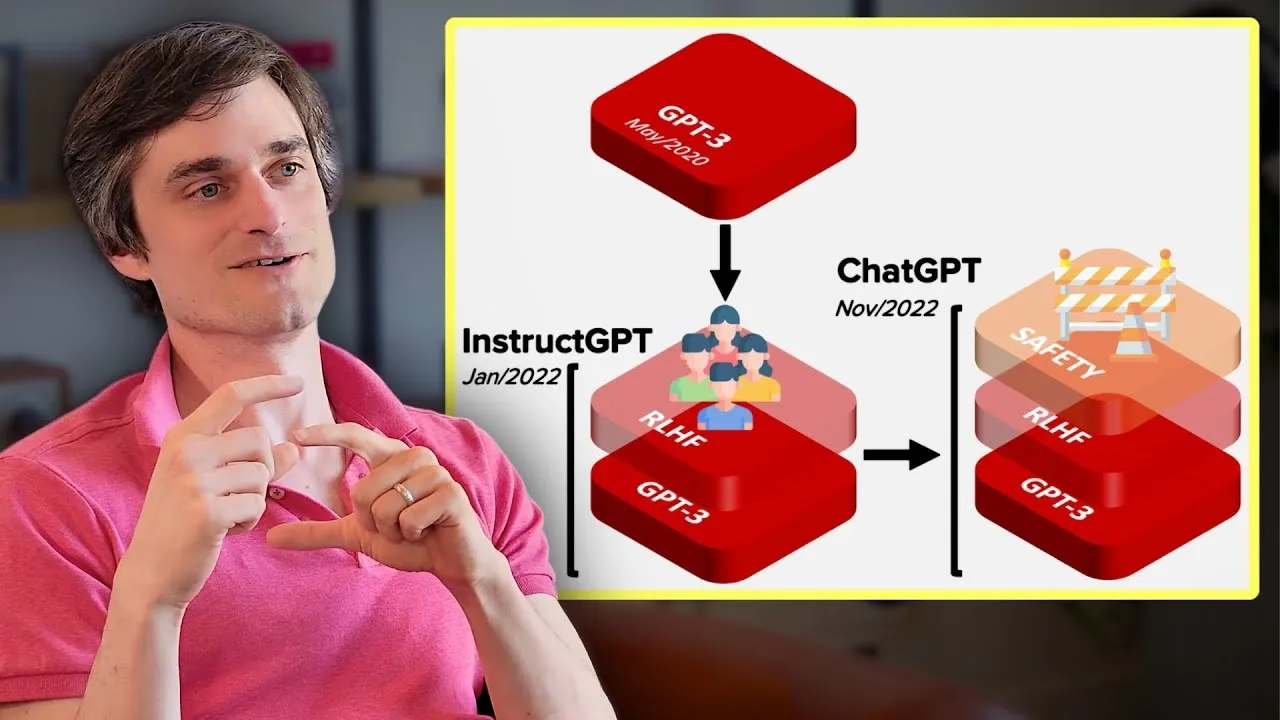
OpenAI cofounder John Schulman explains how ChatGPT emerged from instruction-following research and why chat framing made RLHF dramatically easier to label.
- ChatGPT was built on GPT-3.5, which finished training in early 2022 and proved surprisingly strong at code.
- Google’s LaMDA and Meena preceded ChatGPT but were persona/fun-focused, not functional assistants.
- GPT-4 finished training in August 2022; early instruction-tuned GPT-4s were impressive but hallucinated and gave unhinged outputs.
- The breakthrough was mixing instruct and chat datasets together to get reliable, self-aware behavior.
- Chat framing made human data labeling far easier: labelers intuitively understood what a helpful robot should do, unlike the vague instruct task.
- Iterative supervised fine-tuning on model-edited outputs (not raw human data) was essential; pure human-written data is hard for models to fit.
- Someone with API access to GPT-3.5 fine-tuning could have built something close to ChatGPT, but iterative RL-style training was the non-trivial differentiator.
2024-05-20 · Watch on YouTube


