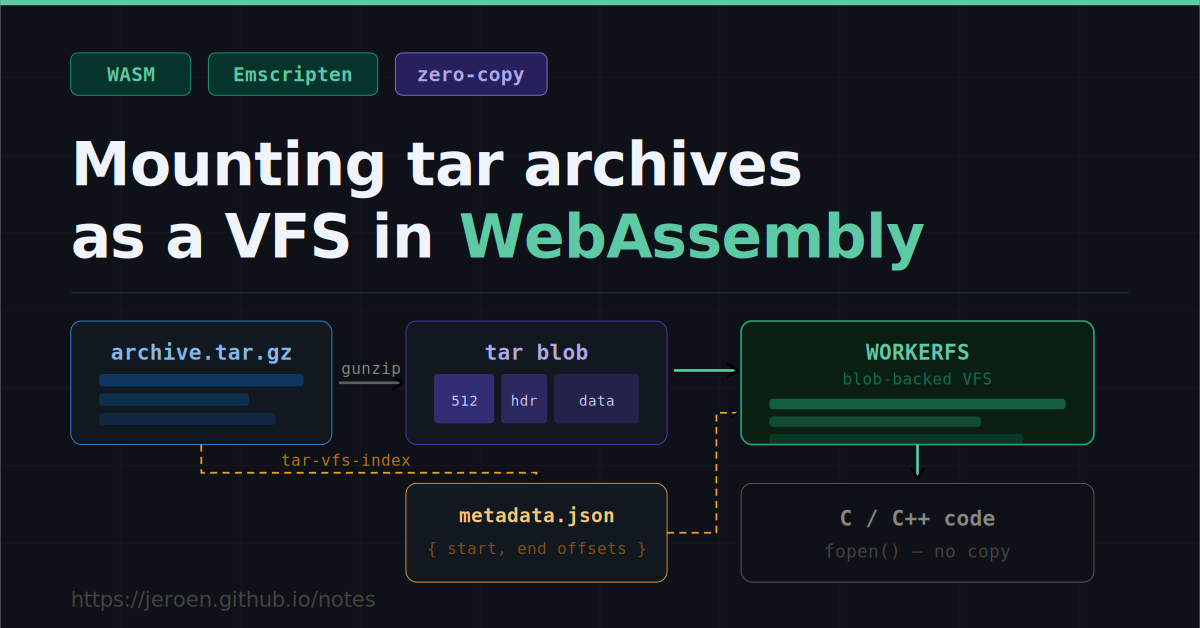
Generate a JSON byte-offset index for files inside a .tar.gz, then mount the decompressed tar blob directly into Emscripten’s WORKERFS without extracting any files.
Key Takeaways
tar-vfs-index npm package reads a tar or tar.gz stream and outputs a JSON index in file_packager metadata format with start/end byte offsets per file.
WORKERFS serves file reads by slicing the backing blob on demand, so zero-copy access is free once the index metadata is shaped correctly.
The browser’s native DecompressionStream handles gunzip before mounting; no extra library needed.
The index can be appended directly inside the tarball as an extra tar entry, producing a self-contained .tar.gz that needs no separate .json fetch.
WebR ships all R packages this way, achieving load times roughly equal to download-plus-decompress time with no additional memory copying overhead.
Hacker News Comment Review
Commenters split on whether this is the right abstraction: the technique still decompresses the entire archive into memory, so it avoids file extraction overhead but not peak memory usage, which undercuts the “memory constrained” framing.
Alternatives surfaced include Ratarmount (random-access tar mounting on Linux via index), BTFS (torrent-as-filesystem), and SquashFS/cramfs as purpose-built compressed read-only filesystem formats, each avoiding different parts of the pipeline.
One commenter noted that true partial-read of .tar.gz is unsolved here because gzip is not random-access; full decompression is still required before blob slicing works.
Notable Comments
@phiresky: Points out you’re still reading the whole file into memory, so extraction would use the same time and less memory – the win is narrower than claimed.
@Ecco: Asks why not use SquashFS or cramfs, formats actually designed for compressed read-only filesystem access.
@Lerc: Applied the same idea on NeoCities using IndexedDB, encoding the tar inside a PNG to bypass NeoCities’ tar file block.