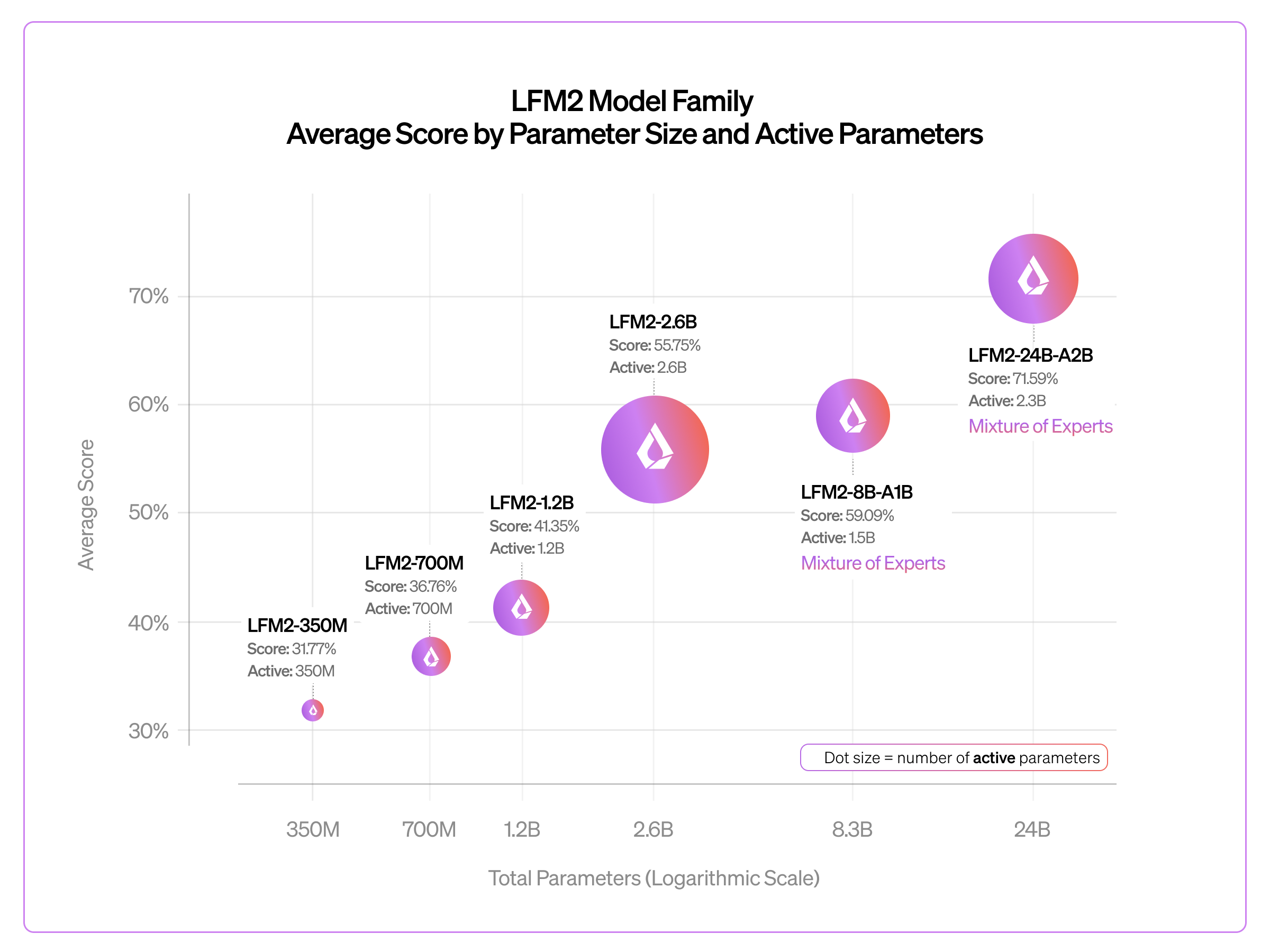
Liquid AI releases LFM2-24B-A2B, a 24B-param sparse MoE model with only 2.3B active per token, fitting in 32GB RAM for edge and cloud deployment.
Key Takeaways
Architecture pairs gated short convolution blocks with GQA at a ~1:3 attention-to-convolution ratio; scales to 40 layers and 64 experts with top-4 routing.
Active parameter count grows only 1.5x (1.5B to 2.3B) while total params triple vs. LFM2-8B-A1B, keeping inference latency edge-friendly.
Benchmarks (GPQA Diamond, MMLU-Pro, MATH-500, IFEval) show log-linear quality gains across the full 350M-to-24B family range.
On a single H100 SXM5 with vLLM, reaches ~26.8K total tokens/sec at 1,024 concurrent requests, beating Qwen3-30B-A3B and gpt-oss-20b.
Day-zero llama.cpp/vLLM/SGLang support with GGUF quantization (Q4_0 through F16); full pre-training at 17T tokens still running, LFM2.5 release pending.