I Built TetrisBench, Where LLMs Compete at Playing Tetris. Here's What I Found.

TLDR
- Yoko Li (a16z) built TetrisBench, pitting GPT-5.2, Claude Opus 4.5, Gemini 3, Grok 4.1, and Sonnet 4 against each other and humans in Tetris as a planning benchmark.
Key Takeaways
- Direct board-to-move prompting failed; reframing as a coding task (models write scoring functions, not pick moves) made play coherent and stable.
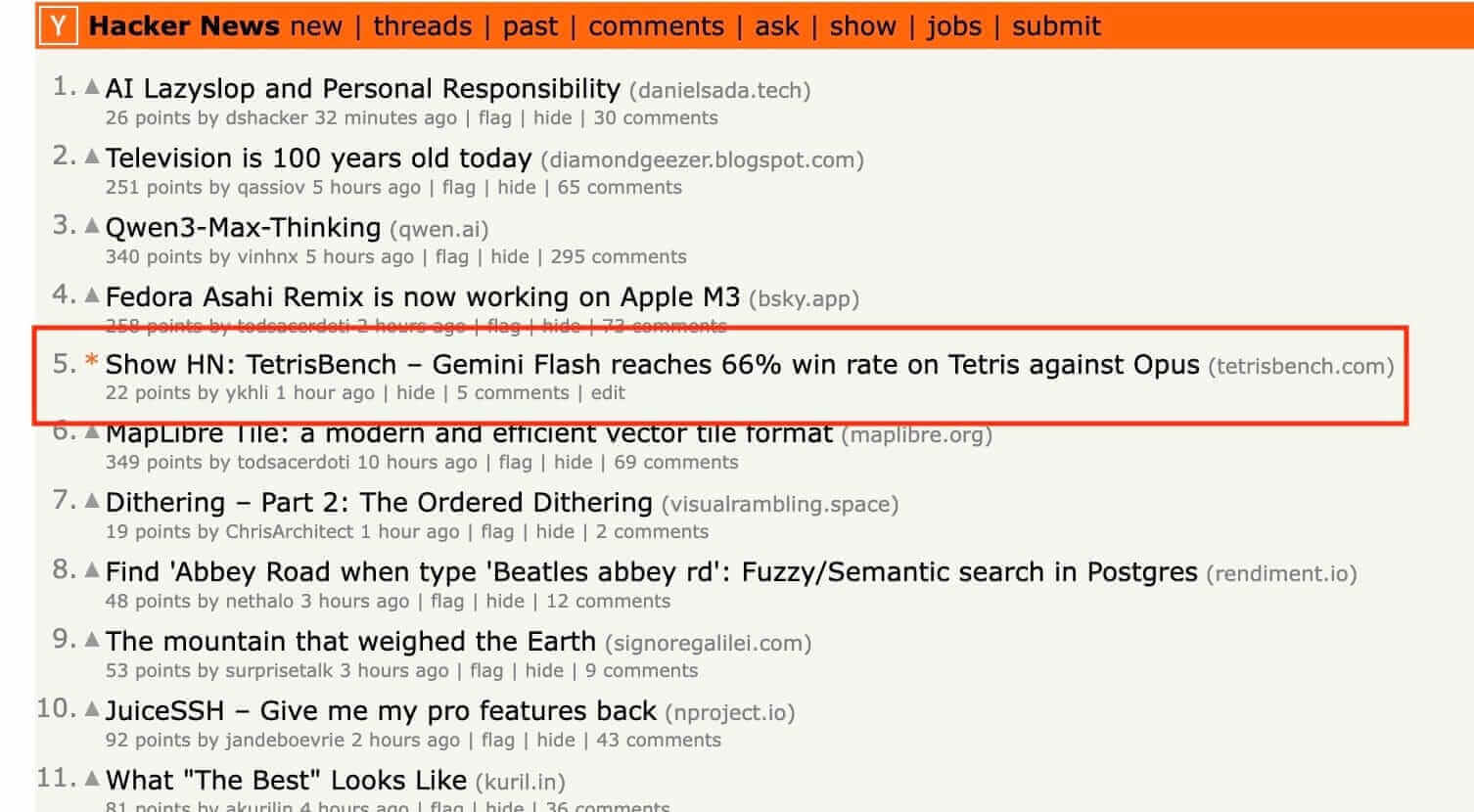
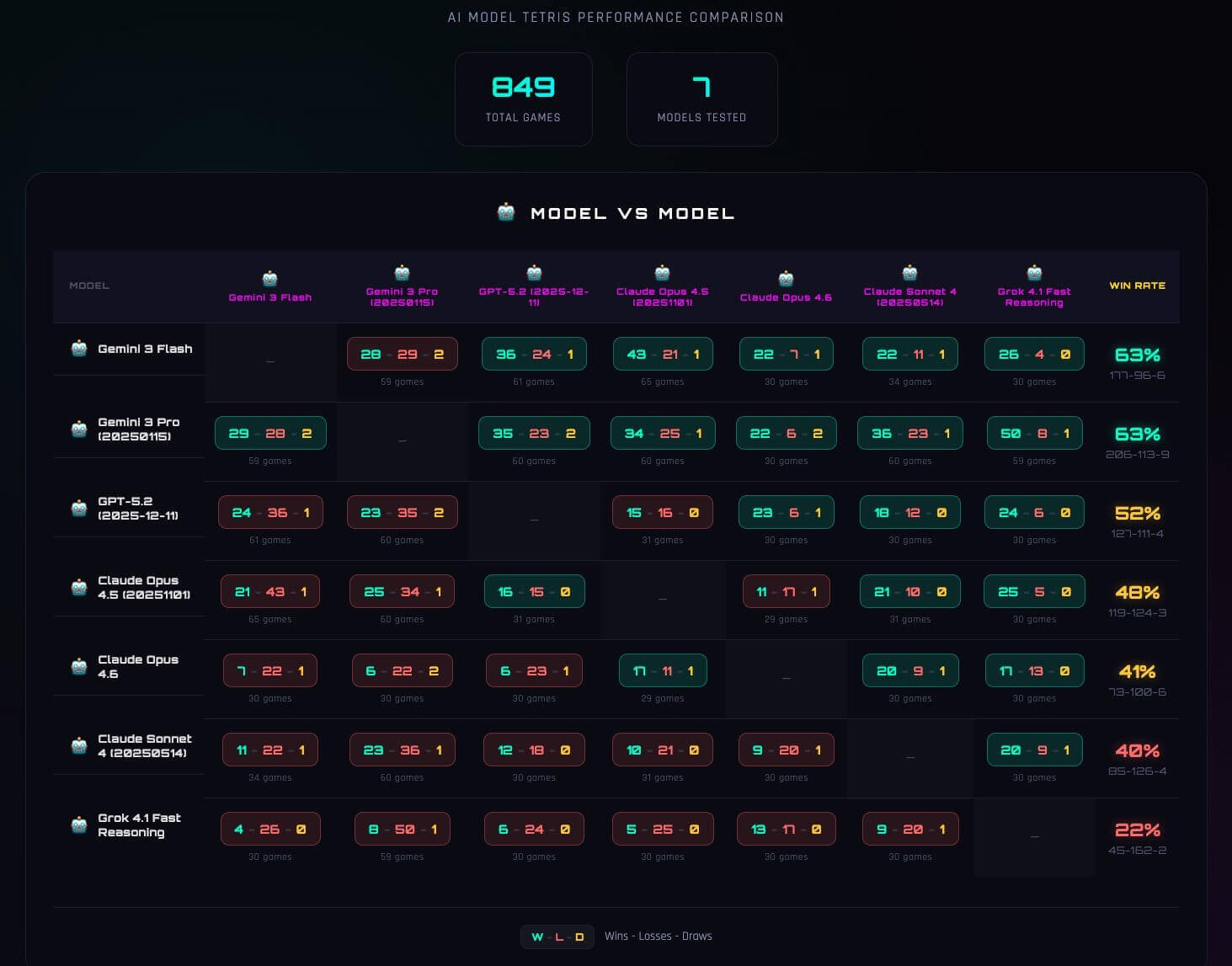
- Gemini 3 Pro achieved the highest win rate (62.0%) with the fewest strategy updates (1.22/game); Gemini 3 Flash won 60.3% with the most updates (2.68/game).
- Frequent strategy interventions showed diminishing returns for some models, causing oscillation rather than convergence on a stable long-term plan.
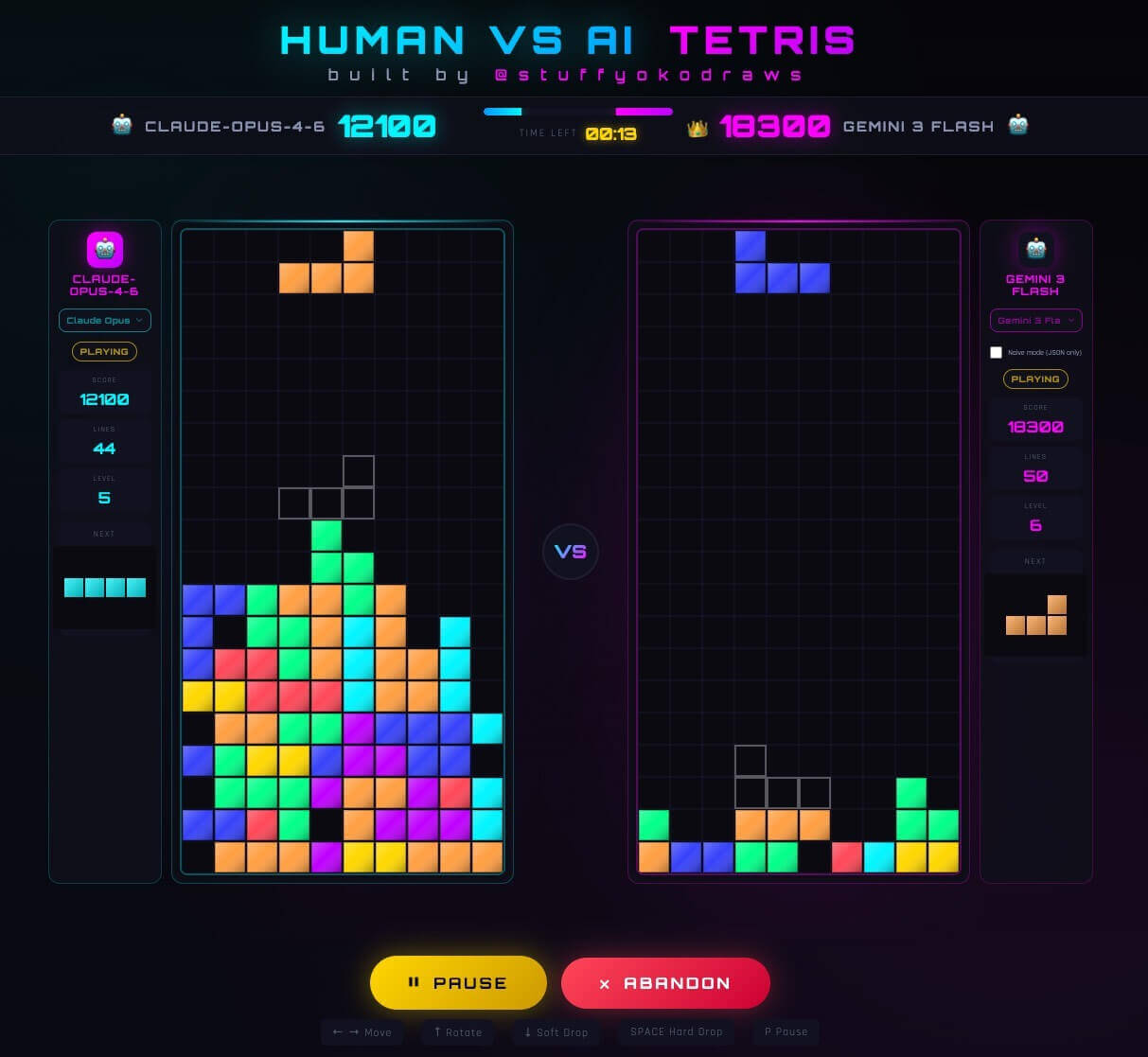
- Top human players beat certain frontier models by introducing controlled board irregularity (bumpiness 12-19, 0-1 holes) that broke AI evaluation functions.
- TAFOKINTS, a competitive Tetris player, scored 22,300 vs. Opus 4.5’s 15,700 by forcing the game into states the model’s heuristics weren’t built for.
Why It Matters
- Optimization horizon and intervention timing are observable in model behavior across hundreds of games, not reliably elicited through prompts alone.
- Structured-state environments like Tetris isolate planning and long-horizon reasoning from perception, surfacing model differences invisible in standard benchmarks.
- The strongest humans exploit off-distribution board states, suggesting current frontier models have brittle heuristics outside their self-induced distribution.
Yoko Li, Andreessen Horowitz · 2026-02-23 · Read the original